Welcome to Aequitas¶
The Aequitas toolkit is a flexible bias-audit utility for algorithmic decision-making models, accessible via Python API, command line interface (CLI), and through our web application.
Use Aequitas to evaluate model performance across several bias and fairness metrics, and utilize the most relevant metrics to your process in model selection.
{kind=link}
Aequitas will help you:
Understand where biases exist in your model(s)
Compare the level of bias between groups in your sample population (bias disparity)
Visualize absolute bias metrics and their related disparities for rapid comprehension and decision-making
Our goal is to support informed and equitable action for both machine learnining practitioners and the decision-makers who rely on them.
Aequitas is compatible with: Python 3.6+
Getting started¶
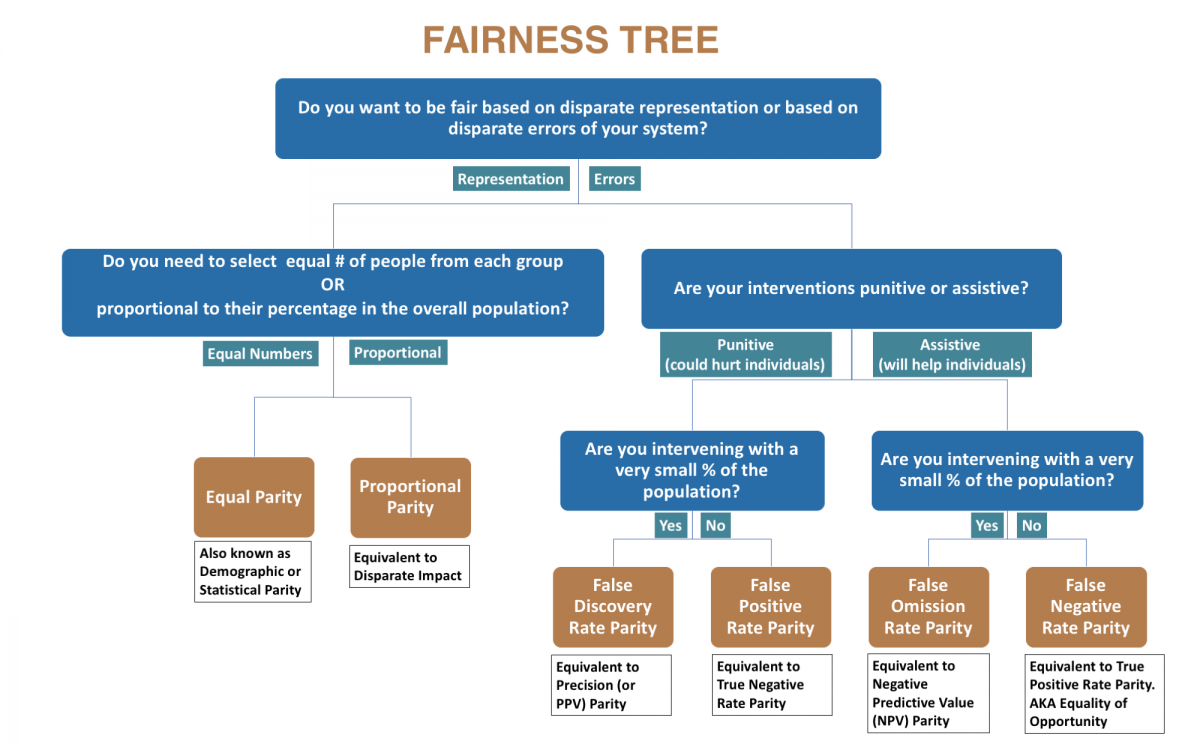
You can audit your risk assessment system for two types of biases:
Biased actions or interventions that are not allocated in a way that’s representative of the population.
Biased outcomes through actions or interventions that are a result of your system being wrong about certain groups of people.
For both audits, you need the following data:
Data about the specific attributes (race, gender, age, income, etc.) you want to audit for the the overall population considered for interventions
The set of individuals in the above population that your risk assessment system recommended/ selected for intervention or action. It’s important t this set come from the assessments made after the system has been built, and not from the data the machine learning system was “trained” on if you’re using the audit as a factor in model selection.
If you want to audit for biases due to model or system errors, you also need to include actual outcomes (label values) for all individuals in the overall population.
Input data has slightly different requirements depending on whether you are using Aequitas via the webapp, CLI or Python package. In general, input data is a single table with the following columns:
scorelabel_value(for error-based metrics only)at least one attribute e.g.
race,sexandage_cat(attribute categories defined by user)
Bias measures tailored to your problem¶
After installing on your computer
Run aequitas-report on COMPAS data:
compas_for_aequitas.csv excerpt:
score |
label_value |
race |
sex |
age_cat |
|---|---|---|---|---|
0 |
1 |
African-American |
Male |
25 - 45 |
1 |
1 |
Native American |
Female |
Less than 25 |
aequitas-report --input compas_for_aequitas.csv
Note: Disparites are always defined in relation to a reference group. By default, Aequitas uses the majority group within each attribute as the reference group. Defining a reference group
The Bias Report produces a pdf that returns descriptive interpretation of the results along with three sets of tables.
Fairness Measures Results
Bias Metrics Results
Group Metrics Results
Additionally, a csv is produced that contains the relevant data. More information about output here.
In the command line you will see The Bias Report, which returns counts for each attribute by group and then computes various fairness metrics. This is the same information that is captured in the csv output.
___ _ __
/ | ___ ____ ___ __(_) /_____ ______
/ /| |/ _ \/ __ `/ / / / / __/ __ `/ ___/
/ ___ / __/ /_/ / /_/ / / /_/ /_/ (__ )
/_/ |_\___/\__, /\__,_/_/\__/\__,_/____/
/_/
____________________________________________________________________________
Bias and Fairness Audit Tool
____________________________________________________________________________
Welcome to Aequitas-Audit
Fairness measures requested: Statistical Parity,Impact Parity,FDR Parity,FPR Parity,FNR Parity,FOR Parity
model_id, score_thresholds 1 {'rank_abs': [3317]}
COUNTS::: race
African-American 3696
Asian 32
Caucasian 2454
Hispanic 637
Native American 18
Other 377
dtype: int64
COUNTS::: sex
Female 1395
Male 5819
dtype: int64
COUNTS::: age_cat
25 - 45 4109
Greater than 45 1576
Less than 25 1529
dtype: int64
audit: df shape from the crosstabs: (11, 26)
get_disparity_major_group()
number of rows after bias majority ref group: 11
Any NaN?: False
bias_df shape: (11, 38)
Fairness Threshold: 0.8
Fairness Measures: ['Statistical Parity', 'Impact Parity', 'FDR Parity', 'FPR Parity', 'FNR Parity', 'FOR Parity']
...