Intro to SQL#
You've already used databases. Excel spreadsheets are a simple example. But those databases have many problems, such as * size of data you can use is limited by RAM * cannot handle complex data (there are databases to handle more complex data types, e.g. documents) * difficult to use data from multiple tables/sheets * no data integrity guarantees (you can accidentally put a letter in a numeric column and the entire column will become a character column) * it's difficult for multiple people to use the spreadsheet at the same time. If one person updates sheet A and another person updates sheet B, integrating both updates gets ugly.
Things to cover:
selectfromlimit(Postgres)wheregroup byorder by
So, let's get into it, shall we!?
First, we'll need to either:
1. use psql
* ssh into the server
* Run psql
2. use dbeaver
Getting a sense of the tables and data:#
A few things we can do to explore:
Using PSQL:
* Look at the schemas currently present; make sure yours is there: type \dn
* List databases: \l
* (This doc has a list of some other quick exploratory commands.)
* Find the count of the list of rows:
SELECT COUNT(*) FROM tablename;
- Output the list of columns for this table:
SELECT column_name
FROM information_schema.columns
WHERE table_name = 'mytablename';
- If you also want to look at data types:
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'mytablename';
Ok, now that we've gotten a sense of the data, let's dial it back and get to the basics. :)
SELECT and FROM#
Now, let's look a bit more into SELECT. The SELECT statement is used to select data from a database. The data returned is stored in a result table, called the result-set.
In SQL, data is usually organized in various tables. For example, a sports team database might have the tables teams, players, and games. A wedding database might have tables guests, vendors, and music_playlist.
First off, let's select everything from the table to see what we get:
SELECT *
FROM mytablename;
There's a lot to view at once here. Let's say we're not interested in all those comments and just want to look at the columns inspection_id, dba_name, aka_name, results, and inspection_date. We can edit the above command to only select those columns:
SELECT inspection_id, dba_name, aka_name, results, inspection_date
FROM inspections;
LIMIT#
Often, tables contain millions of rows, and it can take a while to grab everything. If we just want to see a few examples of the data in a table, we can select the first few rows with the LIMIT keyword. (This might remind you of using .head in pandas.)
SELECT inspection_id, dba_name, aka_name, results, inspection_date
FROM inspections
LIMIT 20;
ORDER BY#
The ORDER BY keyword is used to sort the result-set in ascending or descending order.
The ORDER BY keyword sorts the records in ascending order by default. To sort the records in descending order, use the DESC keyword.
Here's how you might order by dba_name in ascending order:
SELECT inspection_id, dba_name, aka_name, results, inspection_date
FROM inspections
ORDER BY dba_name;
Now, try altering the above line so that it orders the list in descending order. How might we do that? Can look here for help.
ORDER BY / LIMIT COMBO
If you use ORDER BY and then LIMIT, you would get the first rows for that order.
SELECT inspection_id, dba_name, aka_name, results, inspection_date
FROM inspections
ORDER BY dba_name
LIMIT 10;
WHERE#
The WHERE clause is used to filter records. That is, the WHERE class extracts only those records that fulfill a specified condition.
Let's say we only want to look at records where the restaurant name is SUN WAH, so that we can check to see if it's a good time to go to Joe's favorite duck place.
SELECT inspection_id, dba_name, aka_name, results, inspection_date
FROM inspections
WHERE dba_name='SUN WAH';
We'll notice that this does not get us any results... Hmmmm.
Let's try using the LIKE operator!!
SELECT inspection_id, dba_name, aka_name, results, inspection_date
FROM inspections
WHERE dba_name LIKE '%SUN WAH%';
GROUPBY#
The GROUP BY statement is often used with aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the result-set by one or more columns.
For example, if we want to find the amount of times that each restaurant has been inspected over this time frame, we might run:
SELECT dba_name, COUNT(*)
FROM inspections
GROUP BY dba_name;
Let's say you are only concerned with the amount of times that the restaurant failed in this timeframe...
SELECT dba_name, COUNT(*)
FROM inspections
WHERE results LIKE 'Fail%'
GROUP BY dba_name;
JOIN#
A JOIN clause is used to combine rows from two or more tables, based on a related column between them. Let's first look here to look at some ven diagrams of the various types of joins.
We have a table with zip code boundaries. To demonstrate how joins work, let's join the boundaries table to the inspections table!
So, in order to select the dba_name from the inspections table (mpettit_schema.mpettit_table) and the objectid from the gis.boundaries table, we would do something like below. Let's discuss what's happening!
SELECT mpettit_schema.mpettit_table.dba_name, gis.boundaries.objectid
FROM inspections
LEFT JOIN gis.boundaries
ON gis.boundaries.zip=inspections.zip:;
So, something went wrong. Any idea what it was?
Let's investigate...
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = inspections';
&
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = 'boundaries';
We see the problem is that the data types for zip code don't match up between the two tables. Let's fix that:
SELECT mpettit_schema.mpettit_table.dba_name, gis.boundaries.objectid
FROM inspections
LEFT JOIN gis.boundaries
ON gis.boundaries.zip=mpettit_schema.mpettit_table.zip::varchar;
Also, you might notice that this is extremely wordy... We can write a shorter query if we used aliases for those tables. Basically, we create a "nickname" for that table.
If you want to use an alias for a table, you add AS *alias_name* after the table name.
SELECT inspect.dba_name, bound.objectid
FROM inspections AS inspect
LEFT JOIN gis.boundaries AS bound
ON bound.zip=inspect.zip::varchar;
SQL order of execution:#
The clauses of an SQL query are evaluated in a specific order.
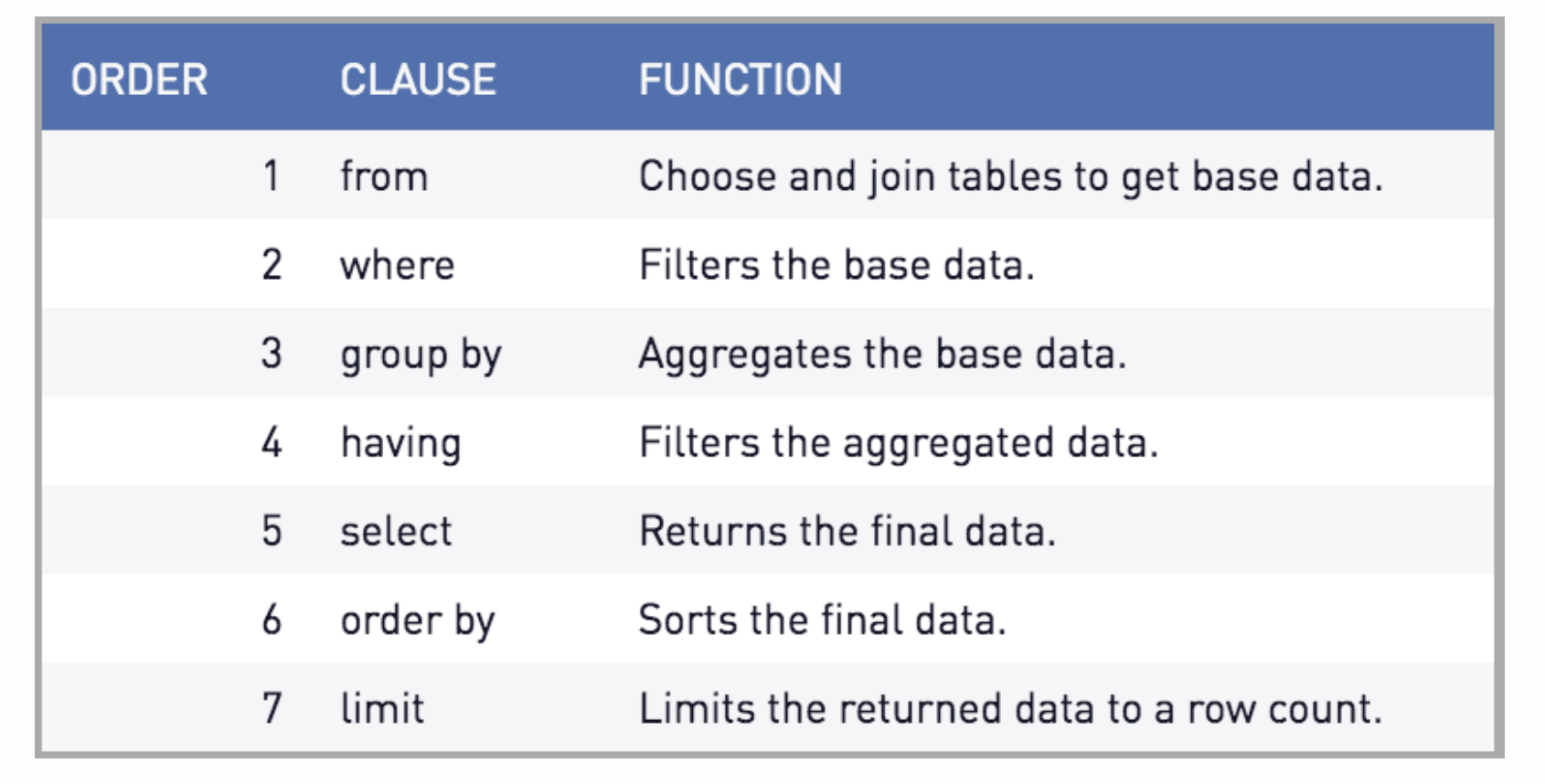
Here is a blog post that goes into a bit more detail.
Joins: SQL's FROM clause selects and joins your tables and is the first executed part of a query. This means that in queries with joins, the join is the first thing to happen.